
How to Scrape Google Images with Python
Images are a crucial part of modern businesses, whether for machine learning, content generation, digital marketing, or research. Companies across various industries require large datasets of images to train AI models, analyze trends, or enrich their content. Manually collecting these images is time-consuming, which is where Google Image Scraping comes into play.
In this guide, we’ll explore how to scrape Google Images with Python using various methods, including requests, BeautifulSoup, and Selenium. Additionally, we will introduce an easier and more efficient alternative—Google Image Search API—for seamless image extraction at scale.
Setting Up Your Python Environment for Web Scraping
Before we start coding, let’s install the necessary libraries for scraping Google Images.
Install Required Python Libraries
Open your terminal or command prompt and install the following packages:
pip install requests
pip install beautifulsoup4
pip install selenium
pip install pillow
pip install webdriver-manager
What Do These Libraries Do?
requests– Fetches the HTML content of web pages.BeautifulSoup4– Parses HTML and extracts useful information like image URLs.Selenium– Automates browser interaction to scrape dynamic content.Pillow– Handles image processing and storage.webdriver-manager– Automatically manages the installation of WebDriver for Selenium.
Inspecting Google Images for Scraping
Before writing the scraper, let’s inspect Google Image Search results to understand how images are loaded.
Steps to Inspect Google Images
- Open Google Images and search for a keyword (e.g., “sunset images”).
- Right-click an image and select Inspect (or press
Ctrl Shift Iin Chrome). - Look for the
srcordata-srcattributes. - Scroll down to see how Google loads more images dynamically using JavaScript.
Because images are dynamically loaded, we need Selenium to scroll down and extract all image URLs.
Method 1: Scraping Google Images Using BeautifulSoup
The simplest way to scrape images is by fetching the HTML content and extracting
Python Code for Scraping Static Google Images
import requests
from bs4 import BeautifulSoup
import os
# Define the search query
query = "sunset images"
search_url = f"https://www.google.com/search?q={query}&tbm=isch"
# Set headers to mimic a real browser
headers = {"User-Agent": "Mozilla/5.0"}
# Fetch the page content
response = requests.get(search_url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
# Extract image URLs
image_tags = soup.find_all("img")
# Create directory to store images
os.makedirs("images", exist_ok=True)
# Download and save images
for i, img in enumerate(image_tags):
img_url = img.get("src")
if img_url:
img_data = requests.get(img_url).content
with open(f"images/image_{i}.jpg", "wb") as f:
f.write(img_data)
print("Images downloaded successfully!")
Limitations of This Approach
- Google dynamically loads images using JavaScript, which
requestsalone cannot handle. - Many images are stored as thumbnails; high-resolution versions need additional requests.
To handle these limitations, we use Selenium.
Since Google Images uses lazy loading (loading images as the user scrolls), we need Selenium to scroll down and extract full-resolution image URLs.
Python Code for Scraping Images with Selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
import os
# Set up Selenium WebDriver
options = webdriver.ChromeOptions()
options.add_argument("--headless") # Run in headless mode
options.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
# Define search query
query = "sunset images"
search_url = f"https://www.google.com/search?q={query}&tbm=isch"
# Open Google Images
driver.get(search_url)
time.sleep(2) # Wait for images to load
# Scroll down multiple times to load more images
for _ in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
# Extract image URLs
image_elements = driver.find_elements(By.CSS_SELECTOR, "img")
image_urls = [img.get_attribute("src") for img in image_elements if img.get_attribute("src")]
# Create directory and save images
os.makedirs("selenium_images", exist_ok=True)
for i, img_url in enumerate(image_urls):
img_data = requests.get(img_url).content
with open(f"selenium_images/image_{i}.jpg", "wb") as f:
f.write(img_data)
print("Images downloaded successfully!")
driver.quit()
Advantages of Using Selenium
- Handles JavaScript-rendered images.
- Scrolls dynamically to load more images.
- Extracts high-resolution versions of images.
Method 3: Scraping Google Images with “Google Image Search API”
For this tutorial, we will use Oxylabs’ Google Image Search API to fetch Google Images related to a specific query. This Google Image scraper allows us to retrieve image URLs, titles, descriptions, and the pages where these images are hosted.
Unlike manual web scraping methods using Selenium or BeautifulSoup, which can lead to CAPTCHAs and IP bans, Oxylabs’ Google Image Search API ensures seamless, automated image retrieval without getting blocked.
Step 1 — Setting Up the Environment
To get started, ensure you have Python 3.6 installed and running on your system. We also need the following libraries to interact with the API and process the results:
requests– For making HTTP requests to Oxylabs' API.pandas– For storing and structuring the extracted image data.
To install these packages, run the following command:
pip install requests pandas
Step 2 — Importing Required Libraries
Create a new Python file and import the necessary libraries:
import requests
import pandas as pd
Step 3 — Structuring the API Payload
Oxylabs’ Google Image Search API allows users to customize their search queries using various parameters. The following payload structure helps us fetch relevant images:
payload = {
"source": "google_images",
"domain": "com",
"query": "sunset",
"parse": "true",
"geo_location": "United States",
"context": [
{
"key": "search_operators",
"value": [
{"key": "filetype", "value": "jpg"},
{"key": "inurl", "value": "image"},
],
}
],
}
Breaking Down the Payload Parameters:
source: Specifies the data source (Google Images).domain: Sets the Google domain (com,uk,de, etc.).query: Defines the search term (e.g.,"sunset").parse: When set totrue, the results are returned in structured JSON format.geo_location: Restricts search results to a specific country (e.g.,"United States").context: Allows applying search filters.filetype: Limits results to a specific image format (e.g.,"jpg").inurl: Ensures images are stored under a specific URL structure (e.g.,"image").
Step 4 — Making the API Request
To fetch the images, we send a POST request to Oxylabs’ API endpoint with authentication credentials:
USERNAME = ""
PASSWORD = ""
response = requests.post(
"https://realtime.oxylabs.io/v1/queries",
auth=(USERNAME, PASSWORD),
json=payload
)
# Extract results
data = response.json()
Make sure to replace and with your Oxylabs API credentials.
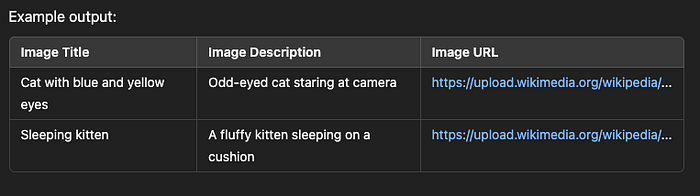
Step 5 — Extracting and Saving Image Data
The response contains structured image data, including image URLs, titles, and descriptions. We extract this information and store it in a Pandas DataFrame for easy processing.
# Extracting image details
results = data["results"][0]["content"]
image_results = results["results"]["organic"]
# Create a DataFrame to store the images
df = pd.DataFrame(columns=["Image Title", "Image Description", "Image URL"])
for img in image_results:
title = img.get("title", "No Title")
description = img.get("desc", "No Description")
url = img.get("url")
df = pd.concat(
[pd.DataFrame([[title, description, url]], columns=df.columns), df],
ignore_index=True,
)
# Save the data to CSV and JSON files
df.to_csv("google_images.csv", index=False)
df.to_json("google_images.json", orient="split", index=False)
print("Image data saved successfully!")
Step 6 — Example Use Case
Let’s say we want to scrape images of cats from Google Images while ensuring that the search results are restricted to images hosted on Wikipedia. We can modify the query and context parameters accordingly:
payload = {
"source": "google_images",
"domain": "com",
"query": "https://upload.wikimedia.org/wikipedia/commons/a/a3/June_odd-eyed-cat.jpg",
"parse": "true",
"geo_location": "United States",
"context": [
{
"key": "search_operators",
"value": [
{"key": "site", "value": "wikipedia.org"},
{"key": "filetype", "value": "jpg"},
{"key": "inurl", "value": "image"},
],
}
],
}
The site search operator ensures that results are only from wikipedia.org. The filetype filter guarantees that we receive JPG images.
Step 7 — Viewing and Exporting the Data
Once the request is processed, the extracted image data is saved in CSV and JSON formats for easy access.
Why Use Oxylabs’ Google Image Search API?

While Python-based scraping methods using Selenium and BeautifulSoup can work, they come with significant challenges:
- IP blocks and CAPTCHAs require constant workaround.
- Google’s dynamic loading makes scraping unreliable.
- Frequent website changes break scrapers, requiring ongoing maintenance.
Advantages of Oxylabs’ API Over Manual Scraping
- Bypasses CAPTCHA & Bot Detection — No need for proxies or CAPTCHA solvers.
- Scalable Solution — Handles large-scale image scraping without IP bans.
- Fast & Efficient — Returns high-resolution images with minimal delays.
- Structured Data Output — Eliminates the need for manual HTML parsing.
- Easy Integration — Simple POST requests provide ready-to-use results.
Instead of worrying about Google’s bot protection, Oxylabs’ Google Image Search API provides a hassle-free, scalable, and legal way to scrape Google Images efficiently.
Final Thoughts
Scraping Google Images with Python is a good choice if you using Selenium, BeautifulSoup, and Requests, but it comes with limitations. IP blocks, CAPTCHA challenges, and JavaScript rendering issues make manual scraping time-consuming and unreliable.
For a faster, more efficient, and scalable solution, Oxylabs’ Google Image Search API is the best choice. With ready-to-use structured results, CAPTCHA-free access, and full automation, it’s the ideal tool for businesses and developers who need high-quality image data.






{kind=link}