

How to Scrape Pinterest in 2025
In this article, I’ll walk you through two simple ways to extract Pinterest data. The first method uses Playwright, a headless browser that lets you interact with web pages like a real user. The second method relies on a Scraper API, which handles everything for you, including CAPTCHAs and dynamic loading. Whether you want complete control or a quick, automated solution, you’ll find an approach that works. Let’s get started!
What Data Can You Extract from Pinterest?
When scraping Pinterest, you can collect:
- Pin Titles — The text describing each pin.
- Pin URLs — Links to individual pins.
- Pin Images — The images associated with each pin.
- User Information — Profile details of the pin creator.
- Post Engagement — Likes, comments, and shares.
Scraping Pinterest with Playwright
Playwright is a powerful tool for scraping dynamic websites. It allows you to interact with JavaScript-heavy pages like Pinterest.
Step 1: Install Playwright
First, install Playwright and its browsers:
pip install playwright
playwright install
Step 2: Write the Scraper
The following Python script searches for pins on Pinterest and extracts their details:
import asyncio
from playwright.async_api import async_playwright
import json
async def scrape_pinterest(query):
url = f"https://www.pinterest.com/search/pins/?q={query}&rs=typed"
results = []
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto(url)
await asyncio.sleep(2)
pins = await page.query_selector_all("div[data-test-id='pinWrapper']")
for pin in pins:
title_element = await pin.query_selector("a")
title = await title_element.get_attribute("aria-label") if title_element else "No title"
pin_url = await title_element.get_attribute("href") if title_element else "No URL"
image_element = await pin.query_selector("img")
image_url = await image_element.get_attribute("src") if image_element else "No image"
results.append({"title": title, "url": pin_url, "image": image_url})
await browser.close()
return results
async def main():
query = "home decor"
data = await scrape_pinterest(query)
with open(f"{query}_pins.json", "w") as file:
json.dump(data, file, indent=4)
if __name__ == "__main__":
asyncio.run(main())
How It Works
- Opens Pinterest and searches for a keyword.
- Waits for the page to load.
- Finds all pins on the page.
- Extracts the title, URL, and image for each pin.
- Saves the data in a JSON file.
This method is useful but can be blocked if Pinterest detects automated scraping.
Scraping Pinterest with Bright Data’s Scraper API
Bright Data provides a web scraper API that makes it easy to collect Pinterest data without worrying about browser automation or getting blocked.
Step 1: Install Requests
pip install requests
Step 2: Use Bright Data’s API
import requests
import json
import time
API_KEY = "YOUR_API_KEY"
KEYWORD = "home decor"
def start_scrape(api_key, keyword):
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"}
data = [{"keyword": keyword}]
response = requests.post(url, headers=headers, json=data)
return response.json().get("snapshot_id")
def get_results(api_key, snapshot_id):
url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f"Bearer {api_key}"}
while True:
response = requests.get(url, headers=headers)
if response.status_code == 200:
with open("pinterest_data.json", "w") as file:
json.dump(response.json(), file, indent=4)
print("Data saved!")
break
elif response.status_code == 202:
print("Waiting for data…")
time.sleep(10)
else:
print("Error:", response.text)
break
if __name__ == "__main__":
snapshot_id = start_scrape(API_KEY, KEYWORD)
get_results(API_KEY, snapshot_id)
How It Works
- Sends a request to Bright Data to start scraping.
- Waits for the data to be processed.
- Downloads and saves the results.
Bright Data’s API is reliable, fast, and avoids Pinterest’s blocks. Check out all the other top scraping APIs.
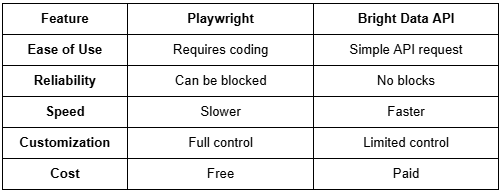
Which Method Should You Use?
Conclusion
Scraping Pinterest is totally doable if you have the right tools. If you like having complete control and don’t mind handling a few roadblocks, Playwright is a great choice. It lets you interact with Pinterest just like a real user, but you might run into blocks.
If you want something easier and more reliable, Bright Data’s API is the way to go. It takes care of everything for you — no dealing with CAPTCHAs or blocked requests.
Both methods can help you collect Pinterest data for research, marketing, or content creation. It all comes down to what works best for you. Pick the approach that fits your needs and start scraping!







{kind=link}